
Throughout the journey of using and implementing Hadoop, there are many reasons that require restarts of various components within the ecosystem. When a configuration update is made, Hadoop requires us to restart many of its components. Below you will find some details on how to avoid having to restart all components and avoiding downtime by creating config groups, and the Do’s and Don'ts of this process.
Our Environment
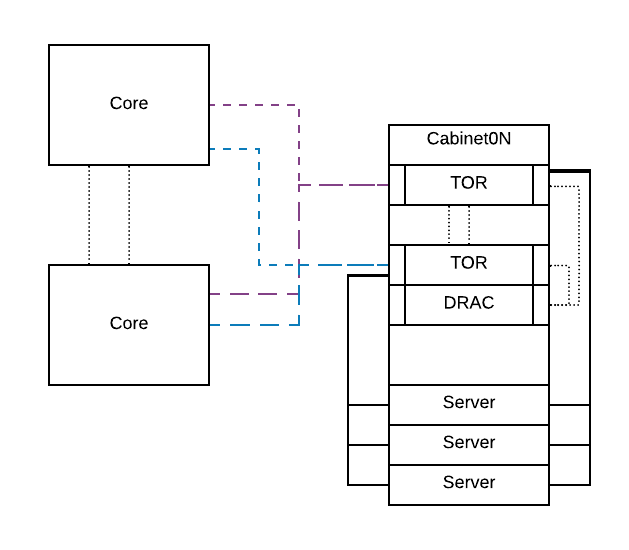
The master servers (NameNode, HMaster) are running on three Dell R630’s and the twelve DataNodes and Region Server are on R740xd all spread across 3 Racks. We also have 4 standby worker nodes set up just in case we need them. On the networking side, each slave node has 2 physical NICs 1 port from each Nic is in a bond together so if one Nic fails there is another. The TOR (Top of Rack switches) are in a 200Gb bond and are in VLT for HA. On the server level these are in a 20Gb bond.
Network Design
Do’s:
1. Always perform a rolling restart with zero failures to stop restarts of components at the first failure helping prevent a cluster-wide problem. Also, restart a single node first to make sure the configuration change did not cause any failures. Sometimes, it could be as simple as a typo other times a white space issue when copy and pasting from different editors or from a development environment. White space issues can be tricky to troubleshoot; it's best to test by restarting a single node first in production even if you have implemented the changes and verified them in a test environment.
2. When restarting Namenodes. Restart Standby first to apply the new configuration, then fail over the Active Namenode so that Standby becomes Active and the Active becomes the standby; this is done by disabling ZKFC on the Active Namenode. Finally you can restart the old Active but now Standby Namenode to apply the new configuration. Make sure it has successfully failed over prior to restarting the previous Active Namenode. (verify on the NameNode UI.) This should only be performed if the original Standby Namenode is backup and healthy.
3. For Hadoop configurations, we set up a separate config group in Ambari for the HBase Master, Region Servers, and client Nodes. Which allows us to update configurations relating only to part of the cluster - Region Servers performance tuning or the NameNode config changes and so on. A particular use case for us was to set xms and xmx resource limits in hbase-env.sh for all Rest and Thrift APIs residing on the Client Nodes. After the changes were made in the client nodes config group in Ambari, we only had to restart services on the client nodes hence avoiding a restart of the DataNodes and Region Servers.
4. We have dedicated client Nodes to run all REST/Thrift APIs, physically separating them from the main cluster. APIs are running under supervisor daemon, which monitors the processes and auto-restarts if one were to fail. Each API is started with a service account and ACls are set to only read and write to its respective Namespace and tables avoiding any human or application errors to other products within the cluster. The client nodes are also where we grant access to the Hbase shell client for developers rather than one of the Master or DataNodes therefore increasing security.
Don’t’s:
1. Do not do a rolling restart before restarting a single node to make sure the changes made are unobjectionable.
2. Do not rush it as you can miss important details or make simple mistakes.
3. Don’t Trust Ambari: Do not trust Ambari always verify on the host itself. We faced an error when we stopped a component from the command prompt and Ambari thought that the service was still running. This can be solved by deleting the pid file under /var/run/<name_of_service> and then starting the component back up from Ambari. Another instance is when Ambari restarts a service and verifies it as started but it dies shortly after within a minute from the new configuration. These all re-enforce point #1 to always perform tests on a single node in all environments.