
Let's discuss centralized logging, and how our framework exists today. Here at Socialgist we have strived to create a robust and efficient solution that I’m happy to share with you now.
Maintaining components and applications across dozens of data sources, it is important to understand their health and activity. When Investigating issues, nobody wants to spend their time trying to locate logs or discovering if they even exist. Operations need to happen in the moment and a centralized logging solution contributes to this ideal.
One of the initial difficulties in designing our framework was finding a solution that met the needs of all of our applications; those that will be created and even our legacy applications. The best solution would be to allow them to continue running, without requiring immediate modification to the source code. This meant taking logs from various sources, events collected in files, kafka topics and even as they are created in containers with applications that otherwise may not have a logging solution.
Some ideas were tossed around our engineering team for a solution to bring all of our logs together, including FileBeat, FluentBit and Fluentd. After some deliberation, tests and comparison, we chose Fluentd, it provided the best option for handling these logs given it’s flexibility, pluggability and inherently low overhead.
While outside developers may contribute with plugins to assist with different tasks in Fluentd, many of the plugins required for our needs were included and simply required some configuration. Fluentd is capable of obtaining logs from a variety of sources.Here is how we are connecting it all together:
- Fluentd: Tail Plugin - allows reading events from text files
- Docker: Fluentd Logging Driver - Docker actually provides a fluentd logging driver to deliver container logs instead of json, file etc.
- Java/Node.js: Libraries are available to deliver events directly to an instance of Fluentd from the application.
Implementing Fluentd in different virtual machines with unique environments have posed some challenges that shouldn’t be overlooked. Various issues have occurred using the Docker images regarding Ruby exceptions with the Kafka plugin. In some cases we were required to change from the alpine image to debian, allowing us to install various libraries required to allow the plugin to successfully work at times.
The tags given to logs, allowing for unique customization by Fluentd, are not retained when delivered to a Kafka topic (as opposed to sending directly to another Fluentd instance, they are retained). Due to this we use another plugin, a record transformer, that allows us to add tags to every log that may be used by the aggregator downstream to distribute logs to the correct index.
In combination with Fluentd, we’ve adapted our use of Elasticsearch and Kibana (EFK) while using Kafka for the message broker between the log forwarders and aggregator. Fluentd forwarders allow each developer to handle logs after they are received with parsing, metrics collection, filtering and other desired modifications. As part of our centralized logging framework, every project or application designated Fluentd forwarder is responsible for handling logs and delivering them to Kafka.
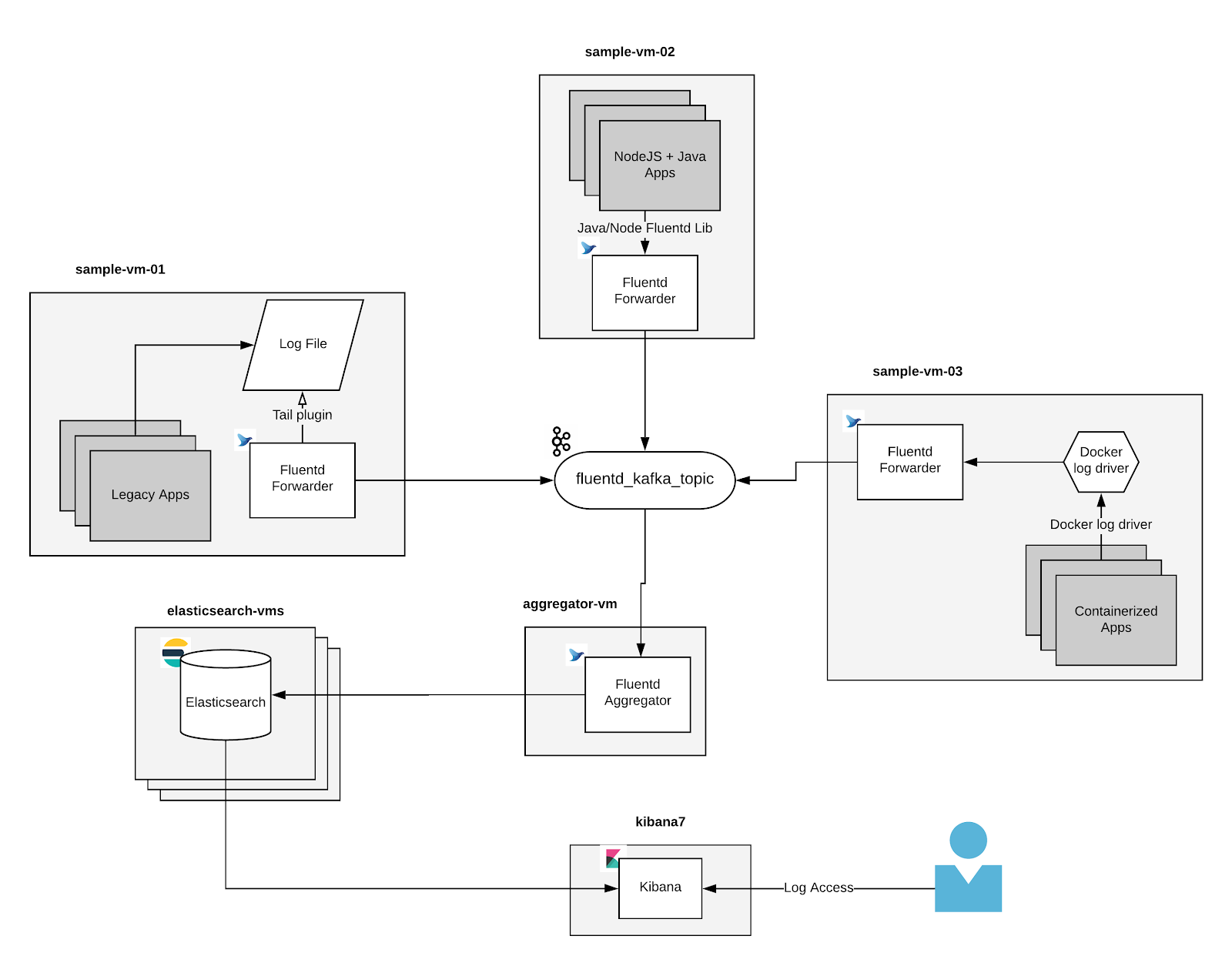
Finally we have a Fluentd Aggregator consuming messages from Kafka, which distributes logs to the appropriate Elasticsearch Indexes. With the collected events Kibana provides a visualization for data within Elasticsearch, which provides a savvy graphical UI for examining these logs.
While there are many ways of obtaining metrics, why not use the collected logs as well? Events happening in applications are constantly being updated to Elasticsearch. In combination with Kibana, or your compatible time series data GUI of choice like Grafana, these events may be graphed to provide insight to trends and relationships, which helps diagnose and improve applications.
After preparing the centralized logging framework and overcoming various obstacles, we have a fluent option for developers to deliver logs so they may be centrally accessible. Logs come from many different sources in a variety of formats, so there tends to be new challenges around the corner with logs not yet collected. Over time it is possible the components in place may need to scale to prepare for a larger logging volume, it’s comforting to know that the framework we have in place is flexible and robust, ready for growth.

